Background
MuleSoft supports processing of messages in batches. This is useful for processing large number of records. MuleSoft has many processors for specific usage in batch processing and implementing business logic. When the batch job starts executing, mule splits the incoming messages into records and stores them in a queue and schedules those records in blocks of records to process. By default, a batch job divides payload with records of 100 per batch, and it concurrently processes using a max of 16 threads. After all the records have passed through all the batch steps, the runtime ends the batch job instance and reports the batch job result indicating which records succeeded and failed during processing.
Batch processing has three phases in Mule 4.
- Load and Dispatch
- Process
- On Complete
Load and Dispatch
This is an implicit phase. This phase creates a job instance, converts the payload into a collection of records and then splits the collection into individual records for processing. Mule exposes batch job instance id through the “BatchJobInstanceId” variable, this variable is available in every step. It creates a persistent queue and associates it with new batch job instance. Every processed record of the batch job instance starts with the same initial set of variables before the execution of the block.
After each record is processed in this phase, the flow continues to execute the dispatched records, asynchronously. It does not wait for the rest of the records to be processed.
Process
In this phase, the batch job instance processes all individual records asynchronously. Batch step in this phase allows for filtering of records. The record goes through a set of Batch Steps that has a set of variables within the scope of each step. A Batch aggregator processor may be used to aggregate records into groups by setting aggregator processor size. There are many processors that could be used to customize the batch processing behavior. For example, an “Accept Expression” processor may be used to filter out the records that do not need processing, any record that evaluates to “true” is forwarded to continue processing.
A Batch job processes large number of messages as individual records. Each Batch Job contains functionality to organize the processing of records. Batch job continues to process all the records and segregates them as “Successful” or “Failed” through each batch step. It contains the following two sections, “Process Records” and “On Complete”. The “Process Records” section may contain one or more “Batch Steps”. Any record of the batch job goes through each of these process steps. After all the records are processed, the control is passed over to the On Complete section.
On Complete
On Complete section provides summary of the processed record set. This is an optional step and can be utilized to publish or log any summary information. After the execution of entire batch job, the output becomes a BatchJobResult object. This section may be used to generate a report using information such as the number of failed records, succeeded records, loaded records, etc.
Batch Processing Steps
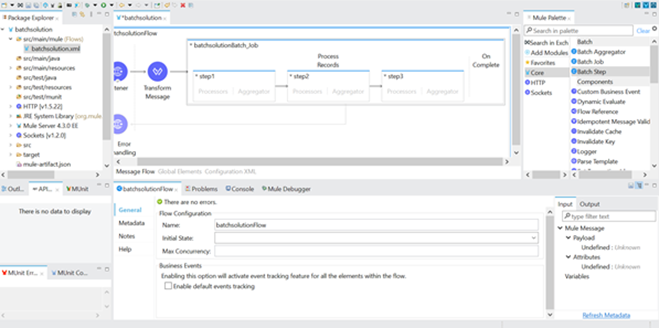
- Drag and drop flow with http listener and configure the listener.
- In the example below, 50 records are added to the payload that will be processed.
- “Batch Job” processor is used to process all the records from the payload. Each “Batch Job” contains two parts – (1) Process Records and (2) On Complete
- In the “Process Records” the batch step is renamed as Step1. In process records we have multiple batch steps.
- Below screenshot shows multiple batch steps.

- In all the batch steps there is an “Accept Policy” i.e., whether the next step accept or not decided by the “Accept Policy”. There are three values in “Accept Policy”.
- “NO_FAILURES” (default) i.e., Batch step process only succeeded records.
- “ONLY_FAILURES” i.e., Batch step process only failed records.
- “ALL” i.e., Batch step process all the records whether it is failed to process.
- There is an “Accept Expression” in the batch step it has to evaluate to true, then only the record accepted by the next step.
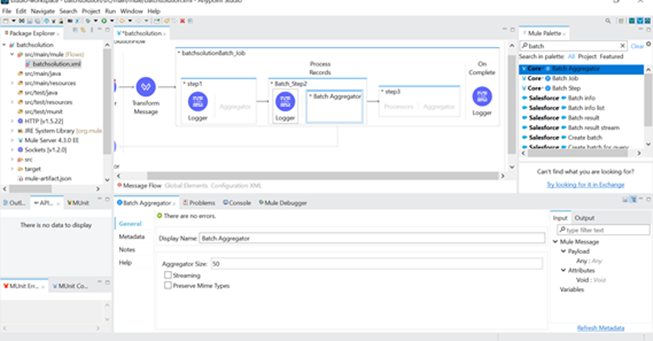
- There is a need to aggregate bulk records, use “Batch Aggregator” by specifying aggregator size as required.
- Below screenshot shows how to configure the batch aggregator.

- Use the logger in the batch aggregator and the configure it.
- All the steps are executed, then the last phase of the job called as “On Complete” will trigger.
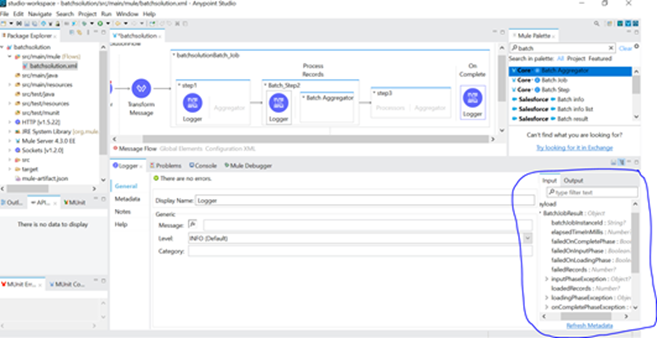
- On Complete phase, there is a BatchJobResult object gives information about, exceptions if any, processed records, successful records, total number of records.
- We can use this BatchJobResult object to extract the data inside it and generate reports out of it.
- Below screenshot shows the BatchJobResult.

- In On Complete phase, if we configure the logger as Processed Records then it will process the Processed Records.
- Run the mule application
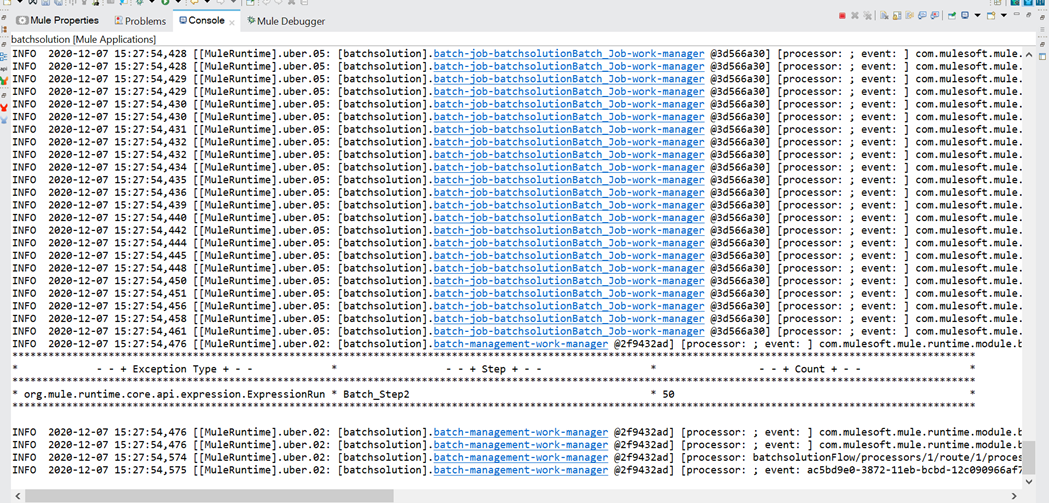
- Give the request in order to trigger the batch job. The batch job sends the payload as one by one records to batch step.
- The screenshot shows the logs in the console.

Performance Tuning
Performance tuning in mulesoft consulting services involves analyzing, improving, validating the millions of records in single attempt. Mule handled to process huge amount of data efficiently. Mule 4 erase the need of manual thread pool configuration as this is done automatically by the mule runtime which optimizes the execution of a flow to avoid unnecessary thread switches.
Consider there are 10 million records to be processed in three steps. Many input operations occur during the processing of each record. The disk characteristics along with workload size, play a key role in the performance of the batch job because during the input phase, an in-disk queue is created of the list of records to be processed. Batch processing requires enough memory available to process threads in parallel. By default, the batch block size is set to 100 records per block. This is the balancing point between the performance and working memory requirements based on batch use cases with various record sizes.
Conclusion
This article show cased the different phases of batch processing, batch job and batch steps. Each batch step in a batch job contains processors that act upon a record to process data. By leveraging the functionality of existing mule processors, the batch step offers a lot of flexibility regarding how a batch job processes records. Batch Processing used for parallel processing of records in MuleSoft. By default, payload divides 100 records a batch. By matching the number of records with respect to the thread count and input payload the batch processing is achieved.