
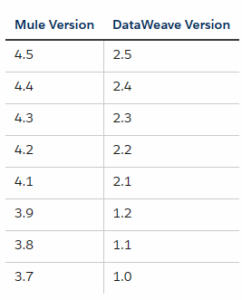
DataWeave is a programming language designed by MuleSoft for accessing and transforming data that travels through a Mule application. Mule runtime engine incorporate it in several core components like Transform and Set Payload, which enable you to execute DataWeave scripts and expressions in your Mule app. These scripts act on data in the Mulesoft Experts event. Most commonly, you use it to access and transform data in the message payload. For example, after a component in your Mule app retrieves data from one system, you can use it to modify and output selected fields in that data to a new data format, then use another component in your app to pass on that data to another system. The following table specifies which version of DataWeave is bundled with each Mule runtime engine release.
Master DataWeave 2.0 with ProwessSoft. Transform complex data formats effortlessly in MuleSoft Integration Solutions using real-world examples, optimized functions, and clean mapping techniques—built for both beginners and integration pros.
Referred link: DataWeave Overview | MuleSoft Documentation
What are some of the features of dataweave?
1. Declarative Syntax: DataWeave uses a declarative syntax, allowing developers to focus on what they want to achieve rather than the steps needed to achieve it. This simplifies code readability and maintenance.
2. Functional Approach: It embraces functional programming paradigms, allowing for operations like mapping, filtering, and reducing data with ease. This approach fosters reusability and modularity in code.
3. Versatility in Data Handling: DataWeave supports various data formats and structures, making it versatile for handling diverse data sources and integration scenarios.
4. Integration and Interoperability: DataWeave plays a pivotal role in bridging the gap between disparate systems, enabling smooth data exchange and communication. It facilitates seamless integration by transforming data into formats compatible with different systems, ensuring interoperability.
5. Data Enrichment and Cleansing: By allowing easy manipulation and enrichment of data, it ensures that the information being processed is accurate, consistent, and ready for analysis. It helps in cleansing data by filtering out irrelevant or erroneous information.
6. Built-in Functions and Libraries: DataWeave comes with an extensive library of functions for handling strings, arrays, objects, and dates. Additionally, custom functions can be created to suit specific transformation needs.
7. Error Handling: DataWeave offers robust error handling mechanisms, enabling developers to anticipate and manage errors effectively during data transformation.
Some of the more advance features of DataWeave:
1. Pattern Matching and Conditional Logic: DataWeave allows pattern matching within data structures, enabling conditional transformations based on specific criteria. This feature is invaluable when dealing with complex datasets that require nuanced handling based on different conditions.
2. Aggregation and Grouping: It offers robust aggregation functions to consolidate data, making it particularly useful in scenarios where summarizing or grouping data is necessary. This feature streamlines tasks like calculating averages, totals, or grouping data elements by specified attributes.
3. Metadata Handling: DataWeave facilitates the manipulation of metadata associated with the data. It allows users to extract, modify, or create metadata, providing a comprehensive toolset for managing data information beyond its raw content.
There are a few hidden gems in dataweave which a lot of folks tend to either ignore or forget to make use of. One such is called Pure Functions and the other Lambda functions.
5. Pure Functions: In the realm of DataWeave, pure functions embody a foundational principle: they maintain consistency and determinism. A pure function operates on specific inputs to generate an output, ensuring that for the same set of inputs, the result remains unchanged, devoid of any side effects. Crucially, these functions confine their actions solely within their scope, refraining from altering external states or relying on external factors. This predictability and lack of dependency on external conditions make pure functions easier to comprehend, test, and reason about. Their deterministic nature foster’s reliability, enabling developers to anticipate and verify outcomes accurately. By steering clear of altering external variables or introducing unexpected changes, pure functions contribute significantly to code stability and maintainability within the DataWeave ecosystem. Despite their simplicity, the significance of pure functions in DataWeave transcends mere predictability. Their consistent behaviour and insulation from external influences serve as pillars for creating robust, testable, and resilient data transformation pipelines. Employing pure functions isn’t just a coding practice; it’s a foundational philosophy that promotes clarity, reliability, and maintainability in data transformation processes within DataWeave.
For example, consider this DataWeave function: fun addTwoNumbers(num1, num2) = num1 + num2 The ‘addTwoNumbers‘ function, designed to take in ‘num1‘ and ‘num2‘ as parameters and yield their summation, is an example of a pure function within the realm of DataWeave. Its purity is derived from the consistency in producing an output solely based on the provided inputs, devoid of any external dependencies or alterations to external states.
Lambda functions: often called anonymous, function without an explicit name. These functions operate similarly to named functions but lack the formal identifier. This characteristic makes them particularly useful for concise, on-the-fly implementations, especially within DataWeave transformations, where quick, compact functions enhance code readability and efficiency. They are often used in it for short and concise operations. Lambda functions can be passed as arguments to higher-order functions or used inline within expressions.
In DataWeave, lambda functions are defined using the (| … |) syntax, where the parameters are specified within the pipes (|) and the function body follows the arrow (->). Consider an example of a lambda function that doubles a number: fun doubleNumber = (num) -> num * 2 Here, doubleNumber is a lambda function that takes a “num” parameter and returns its double value. This lambda function can be used within other functions or expressions. Now let’s look at some of the common Best Practices to be followed while using dataweave.
1. Modularity and Reusability: Encapsulate common transformations into reusable functions or modules, promoting modularity and simplifying maintenance.
2. Error Handling: Implement robust error handling mechanisms to gracefully manage unexpected scenarios, ensuring smooth data processing.
3. Performance Optimization: Strive for optimized performance by leveraging DataWeave’s built-in functions and avoiding unnecessary operations.
Any code that we write in any language must be an optimized piece of code. Dataweave is no such exception. There are a few ways to look at the optimization of the dataweave codes that we write.
1. Streaming Processing: Utilize DataWeave’s streaming capabilities to process large datasets more efficiently. Streaming processes allow for data handling in smaller, manageable chunks, reducing memory overhead.
2. Selective Usage of Functions: While DataWeave offers a plethora of functions, judiciously selecting and employing only necessary functions aids in optimizing performance. Avoiding unnecessary transformations or redundant operations contributes to faster processing times.
3. Parallel Processing: Leverage parallel processing capabilities within DataWeave for operations that can be executed concurrently. This approach significantly enhances throughput when handling sizable datasets.
Any implementation if it does not have a real-world application, it turns meaningless to use it. Now is the time to look at how dataweave is facing the real-world challenges.
1. API Integration: It plays a pivotal role in API integrations, where data often needs to be transformed from one format to another to facilitate smooth communication between different systems. Its ability to seamlessly convert data structures ensures compatibility between APIs, reducing integration complexities.
2. Data Migration and Modernization: During data migration or modernization initiatives, businesses often encounter the challenge of transforming legacy data into contemporary formats. It simplifies this process by enabling swift and accurate data transformation, ensuring a seamless transition.
3. Business Intelligence and Analytics: For organizations relying on data-driven insights, DataWeave becomes instrumental in preparing data for analysis. By cleansing, enriching, and structuring data in the desired format, it enhances the accuracy and reliability of analytical outcomes.
Let’s look at a simple use case to compare two arrays of objects to get common objects using dataweave. Just like the other programming languages, there are multiple ways to achieving the same result, let’s look at a few options. Considering that there are two arrays of objects named “input1” & “input2” which look as shown below:

Possible Solutions: Add input1 and input2 arrays into the input explorer module as shown in pics. Option1: Here, we are going to use join and map functions to get the desired output. Join: join returns an array all the input1 items, merged by lineItemId with any input2 items that exist. Map: Iterates over items in an array (join output) and outputs the results into a desired array.
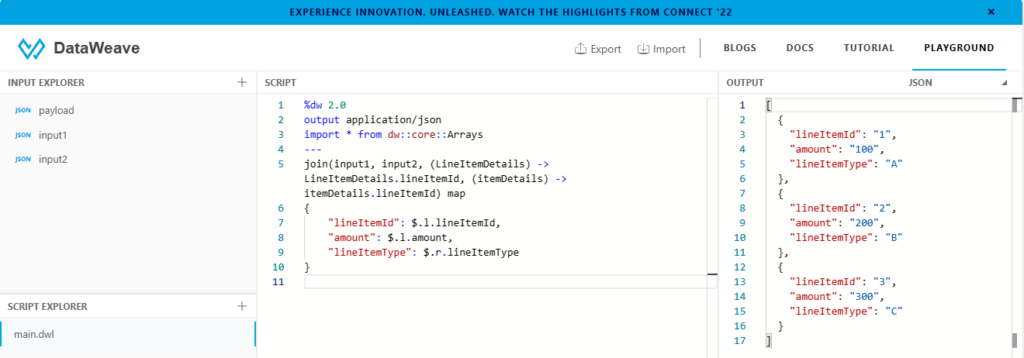
Option2: Using join, map and distinctBy functions to get the desired output. Join: Join returns an array all the input1 items, merged by lineItemId with any input2 items that exist. Map: Iterates over items in an array (join output) and outputs the results into a desired array. distinctBy: The distinctBy function is useful when you need to remove duplicate items from an Array.

Option3: Using map and filter functions to get the desired output. Map: Iterates over items in an array and outputs the results into a desired array. Filter: Iterates over an array and applies an expression that returns matching values. The expression must return true or false. If the expression returns true for a value or index in the array, the value gets captured in the output array.If it returns false for a value or index in the array, that item gets filtered out of the output.If there are no matches, the output array will be empty. Here, we are comparing lineItemId of input1 and lineItemId of input2.
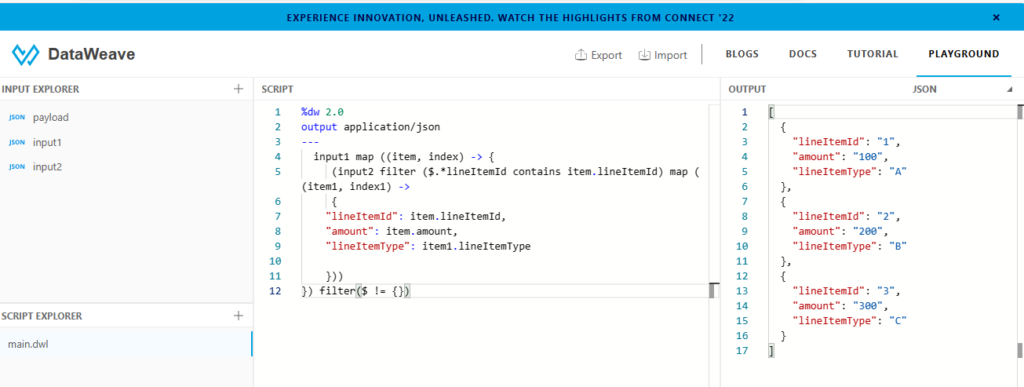
Option5: Using join and map functions to get the desired output. Join: join returns an array all the input1 items, merged by lineItemId with any input2 items that exist. Map: Iterates over items in an array (join output) and outputs the results into a desired array.

You see there are multiple ways to achieve the same output. It depends on the use case and the implementation that will bring out the true essence and power of dataweave. As data ecosystems continue to expand, it is expected to evolve in tandem with emerging technologies. Integration with AI and machine learning for automated data transformation and pattern recognition could be the next frontier. Furthermore, enhancements in real-time processing capabilities and support for new data formats might shape the future trajectory of DataWeave. In a data-centric world where the efficient handling and transformation of information are paramount, it emerges as a versatile and powerful ally. Its comprehensive set of functionalities, ranging from simple transformations to complex data manipulations, makes it an indispensable tool for businesses seeking streamlined data operations. Understanding the nuances of it and harnessing its capabilities not only streamlines data workflows but also empowers organizations to extract meaningful insights from their data assets. Embracing best practices and staying abreast of its evolving features positions businesses at the forefront of efficient data transformation, facilitating informed decision-making and sustainable growth.
